2024年2月1日发(作者:)
transformer的6层decoder的详细结构
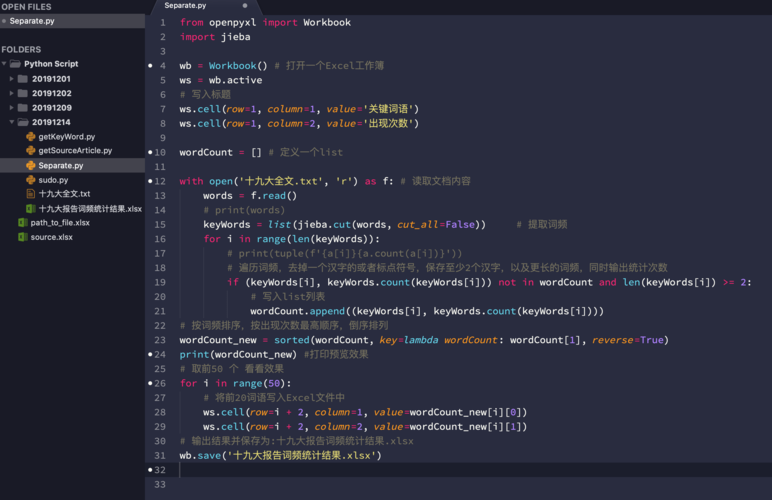
Transformer模型的6层Decoder结构如下所示:
1. 输入嵌入层(Input Embedding Layer):将输入序列中的每个词转换为定长的向量表示。这里的输入是目标语言的序列。
2. 位置编码层(Positional Encoding Layer):为输入序列中的每个位置添加位置编码,以考虑词与词之间的位置关系。
3. 第1个自注意力层(Self-Attention Layer):利用自注意力机制对输入序列进行编码,获得每个位置的上下文表示。
4. 第2个自注意力层(Self-Attention Layer):同样使用自注意力机制,进一步提取上下文信息。
5. 编码-解码注意力层(Encoder-Decoder Attention Layer):利用注意力机制将编码器的输出与目标序列的嵌入进行交互,获得对目标序列的上下文表示。
6. 前馈神经网络层(Feed-Forward Neural Network Layer):应用全连接层和激活函数对上一层的表示进行非线性变换。
7. 输出层(Output Layer):将上一层的表示映射到词表大小的空间上,生成最终的目标语言词汇分布概率。
8. 损失函数(Loss Function):使用交叉熵损失函数计算模型的预测与真实目标序列的差异。
这是Transformer模型的一个Decoder层的结构,而Transformer的Decoder由6个相同的Decoder层堆叠而成,每个Decoder层之间都存在残差连接和层归一化操作,以提高信息流动和模型训练效果。总的来说,Transformer的Decoder层可以通过自注意力机制和编码-解码注意力机制实现对目标序列的上下文建模,并通过前馈神经网络层和输出层进行非线
性变换和预测。每一层都会利用注意力机制聚焦于输入序列中最重要的部分,并捕捉长距离依赖关系,从而更好地生成准确的目标语言序列。

本文发布于:2024-02-01 08:29:38,感谢您对本站的认可!
本文链接:https://www.4u4v.net/it/170674737835253.html
版权声明:本站内容均来自互联网,仅供演示用,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。
| 留言与评论(共有 0 条评论) |
