上一节大概讲了一下LeNet的内容,这一章就直接来用,实际上用一下LeNet来进行训练和分类试试。
调用的数据集:
说明:
如今近视已经成为困扰人们健康的一项全球性负担,在近视人群中,有超过35%的人患有重度近视。近视会拉长眼睛的光轴,也可能引起视网膜或者络网膜的病变。随着近视度数的不断加深,高度近视有可能引发病理性病变,这将会导致以下几种症状:视网膜或者络网膜发生退化、视盘区域萎缩、漆裂样纹损害、Fuchs斑等。因此,及早发现近视患者眼睛的病变并采取治疗,显得非常重要。
数据集实际上用了这么几个部分:
其中DATADIR目录下的图片都是以下形式:
其中照片的成分是按照文件的名称来进行区分的,当其命名规则为P开头的,则代表其为病理性近视,N开头的为正常眼睛,而H开头的则代表为高度近视。
我们将病理性患者的图片作为正样本,标签为1; 非病理性患者的图片作为负样本,标签为0。从数据集中选取两张图片,通过LeNet提取特征,构建分类器,对正负样本进行分类,并将图片显示出来。
正式开始之前,我们还是要将任务按照流程划分
我们在这次开发中,不仅要训练模型,计算Loss,还需要用数据集对成果进行准确性分析。
定义数据读取器
定义LeNet模型
编写训练过程
定义评估过程
进行模型计算
我们需要读取两部分数据,分别是训练集和评估集,这两个集是分开的
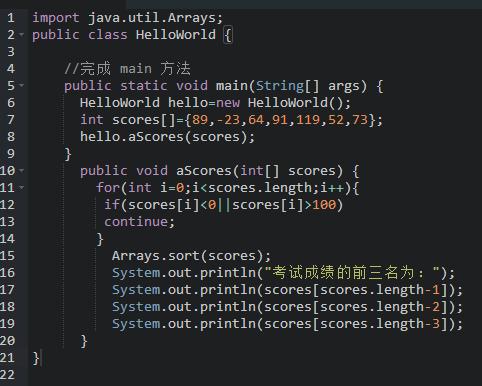
# 对读入的图像数据进行预处理
def transform_img(img):# 将图片尺寸缩放道 224x224img = size(img, (224, 224))# 读入的图像数据格式是[H, W, C]# 使用转置操作将其变成[C, H, W]img = np.transpose(img, (2,0,1))img = img.astype('float32')# 将数据范围调整到[-1.0, 1.0]之间img = img / 255.img = img * 2.0 - 1.0return img
类似之前的,我们需要将训练集划分batch,还需要将其打乱进行。
至于Label,则是由名称决定的
分组读取完毕之后,
# 定义训练集数据读取器
def data_loader(datadir, batch_size=10, mode = 'train'):# 将datadir目录下的文件列出来,每条文件都要读入filenames = os.listdir(datadir)def reader():if mode == 'train':# 训练时随机打乱数据顺序random.shuffle(filenames)batch_imgs = []batch_labels = []for name in filenames:filepath = os.path.join(datadir, name)img = cv2.imread(filepath)img = transform_img(img)if name[0] == 'H' or name[0] == 'N':# H开头的文件名表示高度近似,N开头的文件名表示正常视力# 高度近视和正常视力的样本,都不是病理性的,属于负样本,标签为0label = 0elif name[0] == 'P':# P开头的是病理性近视,属于正样本,标签为1label = 1else:raise('Not excepted file name')# 每读取一个样本的数据,就将其放入数据列表中batch_imgs.append(img)batch_labels.append(label)if len(batch_imgs) == batch_size:# 当数据列表的长度等于batch_size的时候,# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出imgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arraybatch_imgs = []batch_labels = []if len(batch_imgs) > 0:# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batchimgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arrayreturn reader
训练集读取时通过文件名来确定样本标签,验证集则通过csvfile来读取每个图片对应的标签
请查看解压后的验证集标签数据,观察csvfile文件里面所包含的内容
需要注意的是,原先的文件不是csv,而是一个xlsx,不能直接改个后缀就直接用,而是需要使用office或者wps重新保存一下,而且需要注意的是,请使用UTF-8或者gbk格式打开,否则可能会导致无法正确读取文件。
csvfile文件所包含的内容格式如下,每一行代表一个样本,其中第一列是图片id,第二列是文件名,第三列是图片标签,第四列和第五列是Fovea的坐标,与分类任务无关
ID,imgName,Label,Fovea_X,Fovea_Y
1,V0001.jpg,0,1157.74,1019.87
2,V0002.jpg,1,1285.82,1080.47
打开包含验证集标签的csvfile,并读入其中的内容
# 定义验证集数据读取器
def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'):# 训练集读取时通过文件名来确定样本标签,验证集则通过csvfile来读取每个图片对应的标签# 请查看解压后的验证集标签数据,观察csvfile文件里面所包含的内容# csvfile文件所包含的内容格式如下,每一行代表一个样本,# 其中第一列是图片id,第二列是文件名,第三列是图片标签,# 第四列和第五列是Fovea的坐标,与分类任务无关# ID,imgName,Label,Fovea_X,Fovea_Y# 1,V0001.jpg,0,1157.74,1019.87# 2,V0002.jpg,1,1285.82,1080.47# 打开包含验证集标签的csvfile,并读入其中的内容filelists = open(csvfile).readlines()def reader():batch_imgs = []batch_labels = []for line in filelists[1:]:line = line.strip().split(',')name = line[1]label = int(line[2])# 根据图片文件名加载图片,并对图像数据作预处理filepath = os.path.join(datadir, name)img = cv2.imread(filepath)img = transform_img(img)# 每读取一个样本的数据,就将其放入数据列表中batch_imgs.append(img)batch_labels.append(label)if len(batch_imgs) == batch_size:# 当数据列表的长度等于batch_size的时候,# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出imgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arraybatch_imgs = []batch_labels = []if len(batch_imgs) > 0:# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batchimgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arrayreturn reader
这个地方其实上一节也说过了,就是LeNet是如何定义的,详情可以参考
简易机器学习笔记(八)关于经典的图像分类问题-常见经典神经网络LeNet
这里就不过多介绍了,简单放一下代码:
# -*- coding:utf-8 -*-# 导入需要的包
import paddle
import numpy as np
import Conv2D, MaxPool2D, Linear, Dropout
functional as F# 定义 LeNet 网络结构
class Layer):def __init__(self, num_classes=1):super(LeNet, self).__init__()self.num_classes = num_classes# 创建卷积和池化层块,每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化v1 = Conv2D(in_channels=3, out_channels=6, kernel_size=5)self.max_pool1 = MaxPool2D(kernel_size=2, stride=v2 = Conv2D(in_channels=6, out_channels=16, kernel_size=5)self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)# 创建第3个卷积层v3 = Conv2D(in_channels=16, out_channels=120, kernel_size=4)# 创建全连接层,第一个全连接层的输出神经元个数为64self.fc1 = Linear(in_features=300000, out_features=64)# 第二个全连接层输出神经元个数为分类标签的类别数self.fc2 = Linear(in_features=64, out_features=num_classes)# 网络的前向计算过程def forward(self, x, label=None):x = v1(x)x = F.sigmoid(x)x = self.max_pool1(x)x = v2(x)x = F.sigmoid(x)x = self.max_pool2(x)x = v3(x)x = F.sigmoid(x)x = shape(x, [x.shape[0], -1])x = self.fc1(x)x = F.sigmoid(x)x = self.fc2(x)if label is not None:if self.num_classes == 1:pred = F.sigmoid(x)pred = at([1.0 - pred, pred], axis=1)acc = ic.accuracy(pred, paddle.cast(label, dtype='int64'))else:acc = ic.accuracy(x, paddle.cast(label, dtype='int64'))return x, accelse:return x
训练过程实际上和之前文章中提到的训练过程并无二至,实际上还是老一套:
当然了,这次的训练主要目的不是为了进行实际的工作,而是来进行模型准确度的测算,这也是我们在上面为什么读取数据集的时候除了基本的训练集,还添加了一个验证集。
验证集的验证工作其实比较简单,就是把model和验证集的参数传进去,然后让模型的预测和实际结果进行比较,计算出预测值和实际的label值的binary_cross_entropy_with_logits,再求出平均的损失值和准确度
代码如下:
# -*- coding: utf-8 -*-
# LeNet 识别眼疾图片
import os
import random
import paddle
import numpy as npDATADIR = '/home/aistudio/work/palm/PALM-Training400/PALM-Training400'
DATADIR2 = '/home/aistudio/work/palm/PALM-Validation400'
CSVFILE = '/home/aistudio/labels.csv'def train_pm(model, optimizer):print('start training ... ')ain()#定义数据读取器,训练数据读取器和验证数据读取器train_loader = data_loader(DATADIR, batch_size=10, mode='train')valid_loader = valid_data_loader(DATADIR2, CSVFILE)for epoch in range(EPOCH_NUM):for batch_id,data in enumerate(train_loader()):x_data,y_data = dataimg = _tensor(x_data)label = _tensor(y_data)# 运行模型前向计算,得到预测值logits = model(img)loss = F.binary_cross_entropy_with_logits(logits, label)avg_loss = an(loss)if batch_id % 10 == 0:print("epoch: {}, batch_id: {}, loss is: {:.4f}".format(epoch, batch_id, float(avg_loss.numpy())))#反向传播,更新权重,清除梯度avg_loss.backward()optimizer.step()optimizer.clear_grad()model.eval()accuracies = []losses = []for batch_id,data in enumerate(valid_loader()):x_data, y_data = dataimg = _tensor(x_data)label = _tensor(y_data)# 运行模型前向计算,得到预测值logits = model(img)# 二分类,sigmoid计算后的结果以0.5为阈值分两个类别# 计算sigmoid后的预测概率,进行loss计算pred = F.sigmoid(logits)loss = F.binary_cross_entropy_with_logits(logits, label)# 计算预测概率小于0.5的类别pred2 = pred * (-1.0) + 1.0 # 得到两个类别的预测概率,并沿第一个维度级联pred = at([pred2, pred], axis=1)acc = ic.accuracy(pred, paddle.cast(label, dtype='int64'))accuracies.append(acc.numpy())losses.append(loss.numpy())print("[validation] accuracy/loss: {:.4f}/{:.4f}".an(accuracies), np.mean(losses)))ain()paddle.save(model.state_dict(), 'palm.pdparams')paddle.save(optimizer.state_dict(), 'palm.pdopt')#定义评估过程
def evaluation(model,params_file_path):print('')#加载模型参数model_state_dict = paddle.load(params_file_path)model.load_dict(model_state_dict)model.eval()eval_loader = data_loader(DATADIR, batch_size=10, mode='eval')acc_set = []avg_loss_set = []for batch_id, data in enumerate(eval_loader()):x_data,y_data = dataimg = _tensor(x_data)label = _tensor(y_data)y_data = y_data.astype(np.int64)label_64 = _tensor(y_data)# 计算预测和精度prediction, acc = model(img, label_64)# 计算损失函数值loss = F.binary_cross_entropy_with_logits(prediction, label)avg_loss = an(loss)acc_set.append(float(acc.numpy()))avg_loss_set.append(float(avg_loss.numpy()))# 求平均精度acc_val_mean = np.array(acc_set).mean()avg_loss_val_mean = np.array(avg_loss_set).mean()print('loss={:.4f}, acc={:.4f}'.format(avg_loss_val_mean, acc_val_mean))
上述就是LeNet在实际验证中的总全部代码,稍微看懂整理一下即可。我们可以跑一下看看结果
他奶奶的,本来就是个三分法的问题,算出来的准确度才0.5几,那不就和我瞎猜准确度高一点点…
不过也能理解,原来1444x1444的图片压缩到244x244再进行处理,这个精确度能高就有鬼了…
不过这也算是一个全流程的设计与开发,可以参考一下流程,
start training ...
epoch: 0, batch_id: 0, loss is: 0.8100
epoch: 0, batch_id: 10, loss is: 0.6131
epoch: 0, batch_id: 20, loss is: 0.7744
epoch: 0, batch_id: 30, loss is: 0.7073
[validation] accuracy/loss: 0.5275/0.6923
epoch: 1, batch_id: 0, loss is: 0.7042
epoch: 1, batch_id: 10, loss is: 0.6933
epoch: 1, batch_id: 20, loss is: 0.6831
epoch: 1, batch_id: 30, loss is: 0.6810
[validation] accuracy/loss: 0.5275/0.6920
epoch: 2, batch_id: 0, loss is: 0.7451
epoch: 2, batch_id: 10, loss is: 0.6951
epoch: 2, batch_id: 20, loss is: 0.7227
epoch: 2, batch_id: 30, loss is: 0.6579
[validation] accuracy/loss: 0.5275/0.6918
epoch: 3, batch_id: 0, loss is: 0.6808
epoch: 3, batch_id: 10, loss is: 0.6888
epoch: 3, batch_id: 20, loss is: 0.6944
epoch: 3, batch_id: 30, loss is: 0.6829
[validation] accuracy/loss: 0.5275/0.6917
epoch: 4, batch_id: 0, loss is: 0.6855
epoch: 4, batch_id: 10, loss is: 0.6458
epoch: 4, batch_id: 20, loss is: 0.7227
epoch: 4, batch_id: 30, loss is: 0.7857
[validation] accuracy/loss: 0.5275/0.6917
loss=0.6912, acc=0.5325
我们换一种方法,不改变图片的大小了,直接上1444x1444图片,然后把神经元改一下,fc1的全连接层的输入值要改成15123000
# 创建全连接层,第一个全连接层的输出神经元个数为64self.fc1 = Linear(in_features=15123000, out_features=64)
然后这个模型,他奶奶的,跑了快五分钟才跑了一个batch,不知道跑到明天能不能跑出来…跑出来再给大家看看结果
算了笑死,刚刚跑了一下下采样改成600 x 600,结果结果和244 x 244 完全一样,不知道这个对于图片大小到底是不是真的
本文发布于:2024-01-28 09:40:24,感谢您对本站的认可!
本文链接:https://www.4u4v.net/it/17064060286509.html
版权声明:本站内容均来自互联网,仅供演示用,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。
| 留言与评论(共有 0 条评论) |
