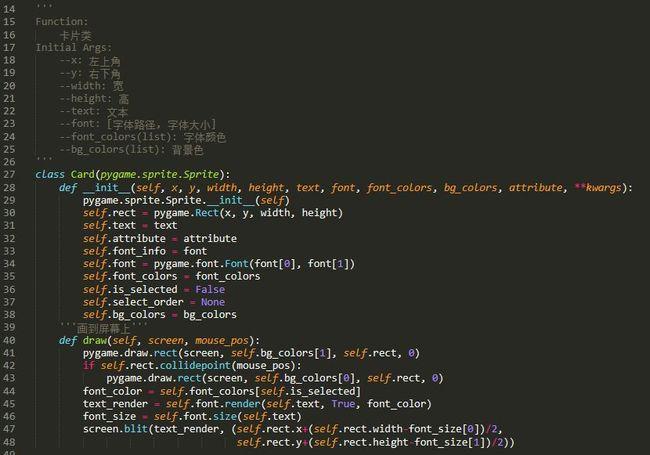
第一部分:HashMap 、HashSet、Hashtable
第二部分:ArrayList、Vector、CopyOnWriteArrayList
第三部分:StringBuffer、StringBuilder
先从以下几个源码方面分析:(JDK1.8)
1、初始容量。2、扩容机制。3、同类型之间对比。
1.1 HashMap:
一、初始容量定义:默认为1 << 4(16)。最大容量为1<< 30
二、扩容加载因子为(0.75),第一个临界点在当HashMap中元素的数量大于table数组长度加载因子(160.75=12),
则按oldThr << 1(原长度*2)扩容。
1.2 HashSet
一、初始容量定义:16。因为构造一个HashSet,其实相当于新建一个HashMap,然后取HashMap的Key。
扩容机制和HashMap一样。
1.3 Hashtable
一、初始容量定义:capacity (11)。
二、扩容加载因子(0.75),当超出默认长度(int)(110.75)=8时,扩容为old2+1。
int newCapacity = (oldCapacity << 1) + 1;
HashTable和HashMap区别
第一,继承不同。
public class Hashtable extends Dictionary implements Map
public class HashMap extends AbstractMap implements Map
第二:*Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用
Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
*
第三,Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,
即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中
是否存在某个键, 而应该用containsKey()方法来判断。
第四,两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
第五,哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
*
第六,Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old2+1。HashMap中hash数组的默认大小是16, 增加的方式是 old2。*
一、初始容量定义:10。
二、扩容:oldCapacity + (oldCapacity >> 1),即原集合长度的1.5倍。
int newCapacity = (oldCapacity * 3)/2 + 1;
2.2 CopyOnWriteArrayList:
CopyOnWriteArrayList在做修改操作时,每次都是重新创建一个新的数组,在新数组上操作,最终再将新数组替换掉原数组。因此,在做修改操作时,仍可以做读取操作,读取直接操作的原数组。读和写操作的对象都不同,因此读操作和写操作互不干扰。只有写与写之间需要进行同步等待。另外,原数组被声明为volatile,这就保证了,一旦数组发生变化,则结果对其它线程(读线程和其它写线程)是可见的。
CopyOnWriteArrayList并不像ArrayList一样指定默认的初始容量。它也没有自动扩容的机制,而是添加几个元素,长度就相应的增长多少。CopyOnWriteArrayList适用于读多写少,既然是写的情况少ÿ
本文发布于:2024-01-30 21:13:56,感谢您对本站的认可!
本文链接:https://www.4u4v.net/it/170662043822886.html
版权声明:本站内容均来自互联网,仅供演示用,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。
| 留言与评论(共有 0 条评论) |
