(/)网址中任意博主的博文目录网址都可爬取(注意是博主的博文目录对应的网址)
1.先获取到所有文章的标题、发表日期、链接
2.通过链接获取文章的内容
3.将文章标题作为“1级”,发表日期和内容作为正文写入word文件
4.保存word文件
5.保存图片到文件夹 注:图片较多,运行出结果,即可停止
注:安装site-packages时,’l.ns import qn #用于应用中文字体‘ pip install 安装出错,经查资料 在 Terminal 中输入 pip3 install python-docx 解决
Beautifulsoup在Pycharm中安装不了的,进入网址,下载对应版本的模板,在Terminal 中输入 pip install 下载的文件(需要在Terminal找到相应的路径,然后执行语句)
| 网址 | 语句 |
|---|---|
| =1001.2014.3001.5501 | pip install |
每段代码含义,作用在代码注释中都有解释
文章只需要更改想要访问的网址,和保存的word文档名称即可(代码本身可以直接使用),看完可以小手点赞收藏呦,谢谢。
#-*- codeing = utf-8 -*-
#@Time : 2021/8/23 20:24
#@Auther : Yt.Monody
#@File : Sina_blog.py
#Software: PyCharmimport requests
from bs4 import BeautifulSoup
import docx
l.ns import qn #用于应用中文字体
import re
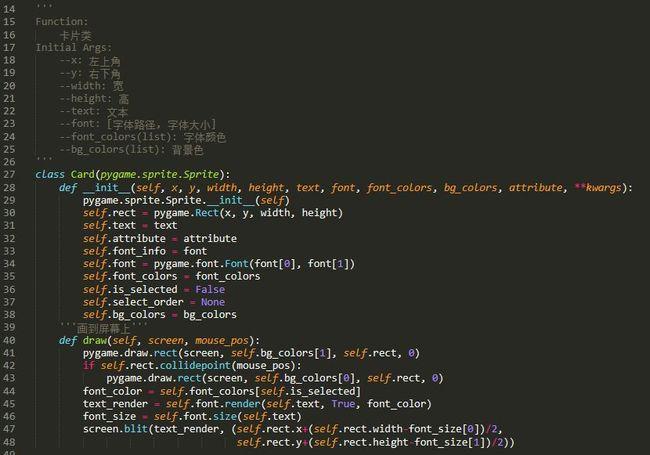
import osdef main(): #主函数#获取博文的 标题,url,时间 存入字典中all_data=getlink()#保存到excelto_word(all_data)#下载图片Sina_pic(all_data)def request_s(url): #访问网页函数headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"}html = (url=url, headers=headers)return htmldef getlink():all_data=[] #用于存放字典# [{},{},{}]#获取博文总页数 爬取的网址不一样,结果可能报错,需要自己去调一下# page=request_s('.html')# soup=t,'lxml')# page_Num=soup.select('.SG_connBody>.article_blk>.SG_page>ul.SG_pages>span')# page_Num=re.findall('>共(.*?)页</',str(page_Num[0]))for i in range(1,2): #如要获取全部博文,请用 <int(page_Num[0])+1> 代替range的第二个参数url = f'{i}.html' #访问网址的动态输入 #<--如要更换博文,在,只需进入博文目录,把1725765581换成对应的 就可以了-->wb_data = request_s(url)soup = BeautifulSoup(t,'lxml')links = soup.select('.atc_title') #解析博文标题times = soup.select('.atc_tm') #解析博文发表日期for i in range(len(links)):all_link = {} #设置空字典http_link = links[i].select('a')[0].get('href') #定位标题所在的标签title = links[i].text.strip() #获得博文文本前后去空time = times[i].text #获得博文发表日期all_link[title] = [http_link, time] #将博文的标题,日期存入字典all_data.append(all_link) #将字典存入列表中print(all_data) #测试 打印字典return all_data# def get_text(all_data): 调试从网页获取文章内容是否有乱码,特殊字符
# #获取文章中的文字
# for data in all_data:
# for url in data.values():
# url =url[0]
# wb_data = request_s(url)
# soup = BeautifulSoup(t,'lxml')
# article = soup.select('.wfont_family')
# # print(article)
# #print(article[0].text)def to_word(all_data):doc = docx.Document() # 新建word文档n",doc.styles['Normal'].font.name = u'宋体'doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')counter = 0 # 计数器,用于记录写入word的文章数n",for example in all_data:for title in example.keys():doc.add_heading(title, 1) #添加标题date = example[title][1][:10] #只去日期,不要时间doc.add_paragraph(date) #添加段落#解析网址wb_data = request_s(example[title][0])soup = BeautifulSoup(t,'lxml')article = soup.select(".wfont_family")# 有些文章被加密,获取不到内容,此时article为空,所以加个if语句判断n",if article:# text = article[0].place("\xa0","")doc.add_paragraph(article[0].text)counter += 1print(f"写入第-{counter}-篇文章: {title} 。")# 中间出现服务器无反应,应考虑反爬虫或其他延时方法",if counter > 150:breakprint(f"共写入 {counter} 篇文章。")doc.save("新浪微博文章.docx")def Sina_pic(all_data): #下载图片picture=[]for data in all_data:for i in data.values():#获取单篇文章中的图片链接url = i[0]wb_data = (url)soup = BeautifulSoup(t,'lxml')img_link = soup.select(".wfont_family")[0].find_all("img")img_link=re.findall('real_src="(.*?)"',str(img_link))picture.append(img_link)# 新浪博文图片if not ists('./新浪博文图片'):os.mkdir('./新浪博文图片')j = 1for pic in picture:for p in pic:img_data&#(url=p).contentimg_path=f'./新浪博文图片/图片{j}.jpg'with open(img_path,'wb') as fp:fp.write(img_data)print(f'图片{j}','下载成功!')j+=1if __name__ == '__main__': #当程序执行时
#调用函数main()print("保存完毕!")
| 0 | docx相关的用法可以参考网址 |
|---|---|
| 1 | .html |
| 2 | 更详细的解释 |
| 3 |
本文发布于:2024-02-04 08:16:36,感谢您对本站的认可!
本文链接:https://www.4u4v.net/it/170702882153871.html
版权声明:本站内容均来自互联网,仅供演示用,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。
| 留言与评论(共有 0 条评论) |
